İçindekiler
Herkese merhaba,
Bu seride baştan sona elimden geldiğince derinlemesine bir şekilde yapay zeka mühendisliği sürecine değineceğiz. Bir yapay zeka geliştiricisi olmak için en temelden ileri seviyeye neler bilmek gerekiyor bunları işleyeceğiz.
Dil Modeli Nedir?
2023 GPT ile birlikte hayatımıza yoğun şekilde giren dil modeli kavramı, aslında bir sonraki kelimeyi istatistik kullanarak tahmin eden bir yapıdır. Konya Etliekmek … şeklinde başlayan bir cümlede üç noktalı alana "Şehridir" kelimesini getiren şey tam da bu — model, var olan metinlerden, cümlelerden ve yapılardan o pattern'i öğrenir.
Dil modelinin temel yapı taşı "Token" dir. Token'lar kullanılan tokenizer'a göre farklılık gösterir; her kelime ayrı bir token olmak zorunda değildir. Aşağıda GPT-5.x için ayarlanmış tokenizer'a göre "Konya Etliekmek Şehridir" cümlesinin nasıl parçalandığını görüyorsunuz — 24 karakter, 9 token.
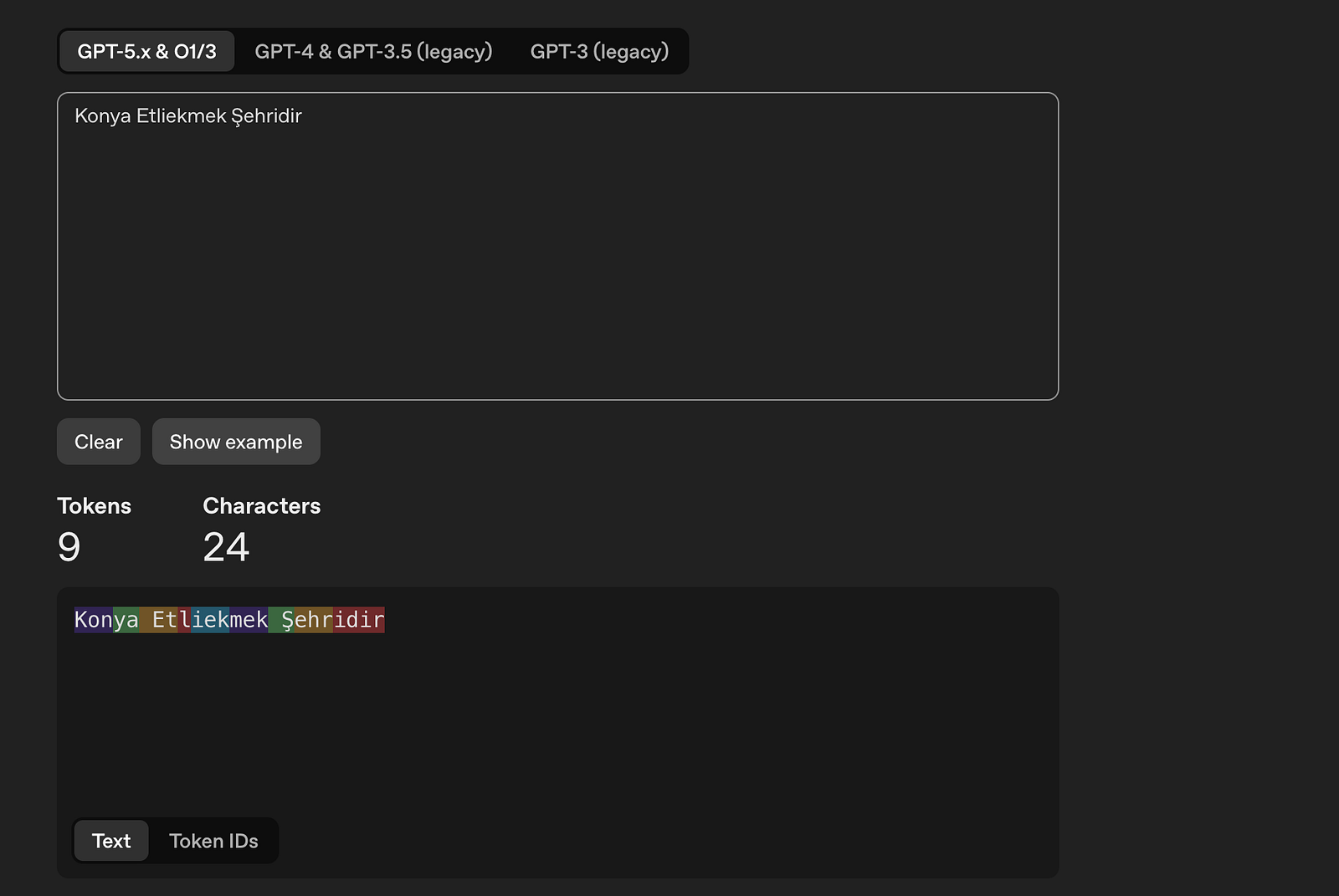
Tokenizer aldığı girdiyi kendi içindeki vocabulary yapısına göre token ID'lerine dönüştürür. Bu noktadan sonra kelimeler anlam taşımaz, sayılara dönüşür. Aynı cümlenin Token ID çıktısı:
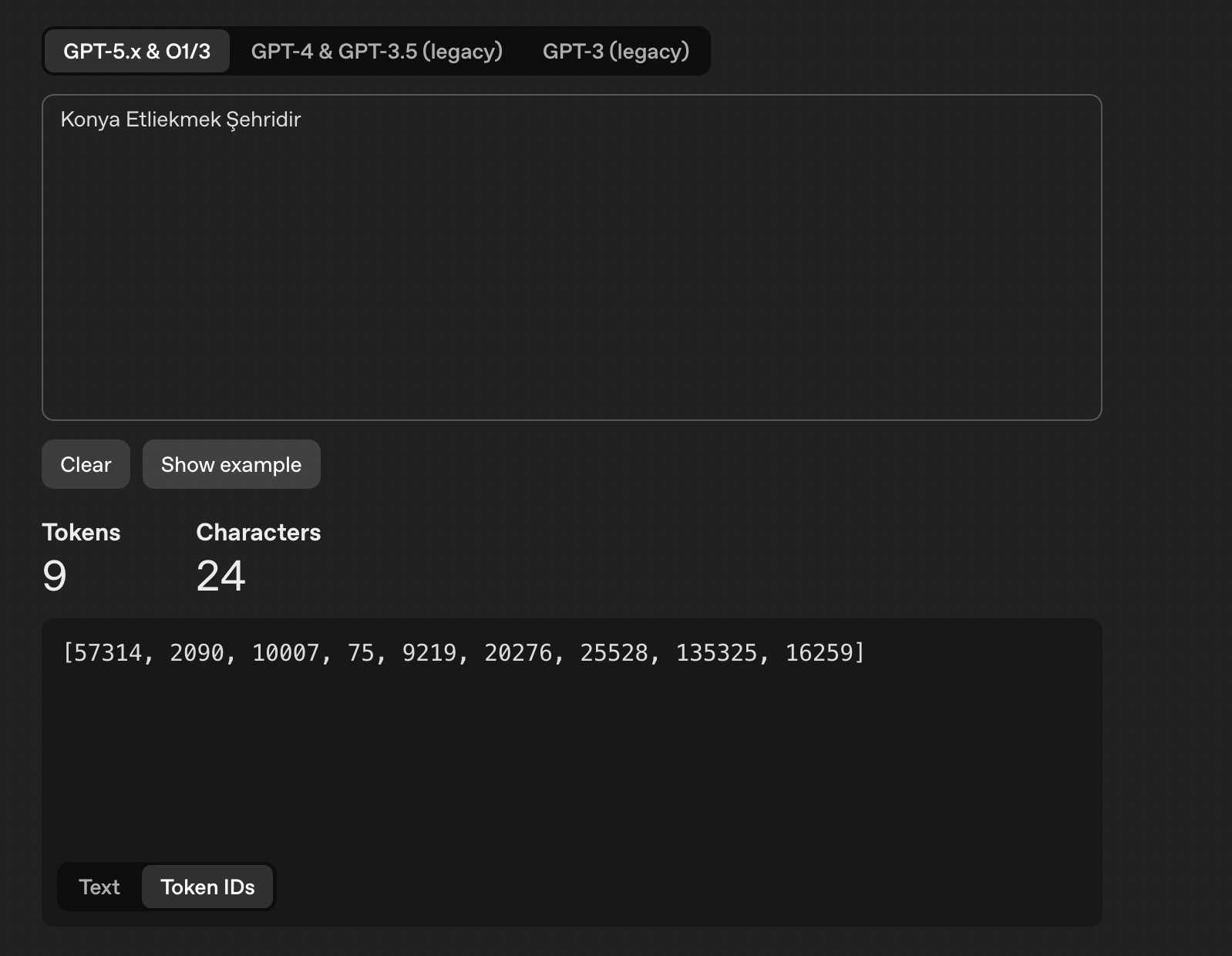
[57314, 2090, 10007, 75, 9219, 20276, 25528, 135325, 16259] — modelin gördüğü şey bu. Bu ID'ler modele input olarak iletilir; Tokenizer → Token ID → LLM akışı şu şekilde işler:
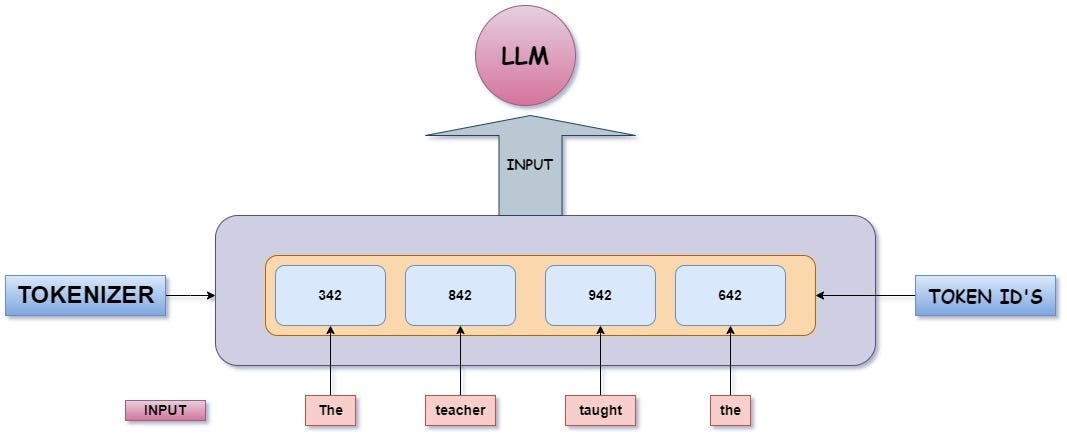
Bu süreçte token ID'ler arasında bazı özel karakterler de var — cümlenin nerede başlayıp bittiğini belli eden, conversation'ı devam ettiren yapılar. Bunlara special token deniyor: <|begin_of_text|>, <|end_of_turn|> gibi. Tokenizer'lar modelden modele değişir; GPT-4 ile Llama aynı metni farklı sayıda token'a bölebilir, bu da maliyet ve bağlam uzunluğu açısından doğrudan fark yaratır.
Dil Modeli Türleri
Temelde iki dil modeli türü var: autoregressive ve masked.
Autoregressive modeller daha önce gelen token'lara bakarak bir sonrakini tahmin eder, onu üretir, sonra onu da bağlama ekleyerek süreci tekrarlar — buna next token prediction deniyor. GPT ailesi bu kategoride. Masked modeller ise farklı çalışır: cümle içindeki gizlenmiş/maskelenmiş değeri bulmaya çalışır. BERT bunun en bilinen örneği. Anlama ve sınıflandırma görevlerinde daha güçlüdür.
Öz Denetimli Öğrenme (Self-supervised Learning)
Peki model bu kadar şeyi nasıl öğreniyor? Burada devreye self-supervised learning giriyor.
Klasik makine öğrenmesinde veriyi etiketlemek zorundasın — "bu fotoğraf kedi, bu köpek" diyerek. Hem pahalı hem yavaş. Dil modellerinde ise farklı bir yaklaşım var: internet üzerindeki milyarlarca metin zaten kendi içinde bir yapıya sahip. Model bu metinlerden bir kısmını maskeleyerek ya da bir sonraki kelimeyi tahmin ederek, etiketsiz veriden kendi kendine öğrenebiliyor.
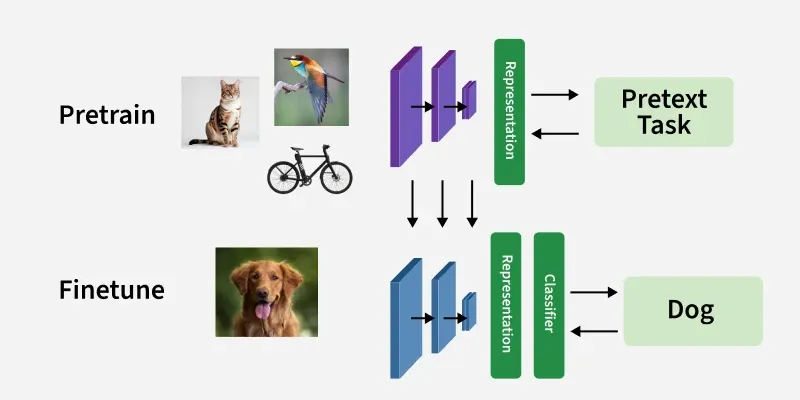
Yukarıda bunu görsel olarak da izleyebilirsin. Pretrain aşamasında model kedi, kuş, bisiklet gibi çeşitli verilerle genel bir temsil öğrenir — amaç bir pretext task çözmek. Fine-tune aşamasında ise bu genel temsil üstüne, spesifik bir görev için (örneğin köpek sınıflandırması) daha küçük ve etiketli veriyle ince ayar yapılır. Bu yaklaşımın en büyük avantajı ölçeklenebilirlik — etiketleme maliyeti olmadan trilyonlarca token üzerinde eğitim yapılabiliyor.
Post-training ve Full Pipeline
Model büyük veriyle pre-training'den geçtikten sonra iş bitmiyor. Eğitimden çıkan ham model istatistiksel olarak tutarlı metin üretir ama senin sorularını anlamak, zararlı içerikten kaçınmak, yardımcı olmak bunlar bu sürecin doğal çıktıları değil. İşte burada post-training devreye giriyor.
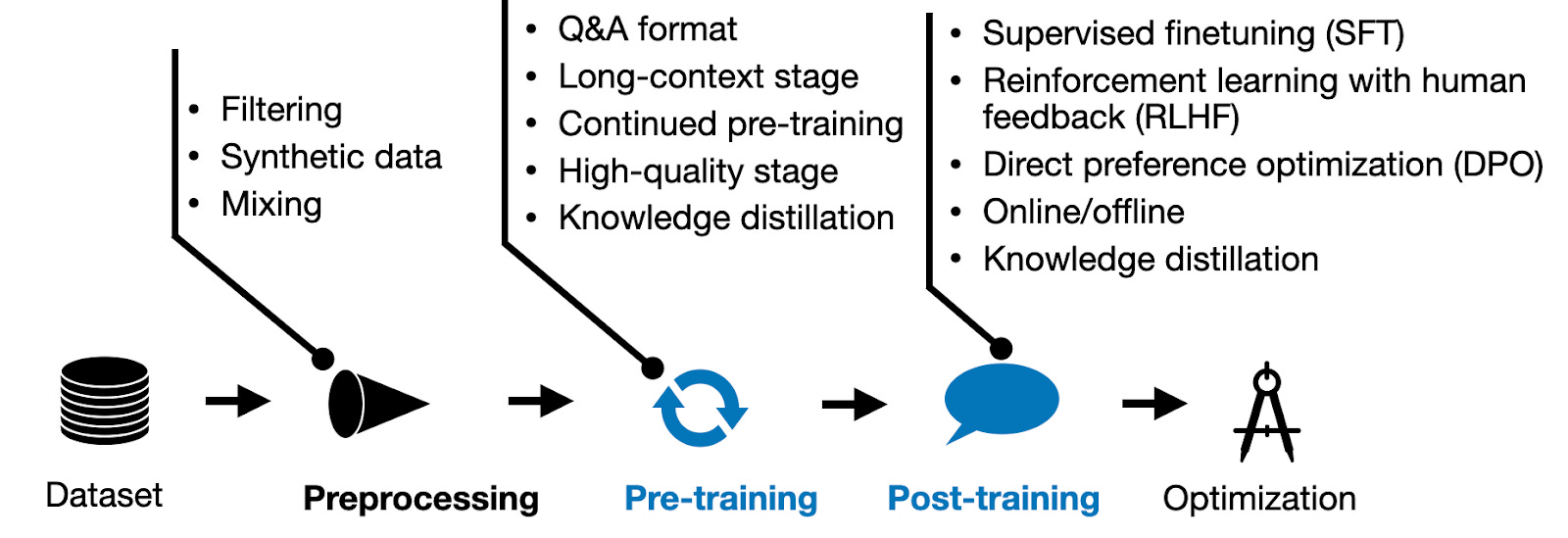
Yukarıda tüm süreci görebilirsin: ham veri preprocessing'den geçer (filtreleme, sentetik veri, harmanlama), ardından pre-training başlar. Post-training aşamasında ise modeli kullanıcı isteklerine uygun hale getiren teknikler devreye girer — Supervised Fine-tuning (SFT), Reinforcement Learning with Human Feedback (RLHF), Direct Preference Optimization (DPO) bunların başında geliyor. En sonunda çıkarım için optimizasyon yapılır.
Post-training vs. Fine-tuning
Bu ikisi sık sık karıştırılıyor, aralarındaki farkı netleştirelim.
Post-training — modeli geliştiren şirket tarafından yapılır. Amaç modeli genel kullanıma hazır hale getirmek: talimatlara uymak, zararlı içerik üretmemek, tutarlı davranmak. OpenAI, Anthropic, Google bunları kendi bünyelerinde uygular.
Fine-tuning — modeli kullanan tarafından yapılır. Amaç modeli belirli bir alana ya da göreve özelleştirmek. Bir şirket kendi destek verisiyle modeli fine-tune edebilir, bir hukuk firması hukuki metinler üzerinde ince ayar yapabilir.
İkisi de "eğitim sonrası süreç" — ama kimin yaptığı ve amacı tamamen farklı.
Çıkarım Optimizasyonu (Inference Optimization)
Model hazır. Ama büyük bir modeli her sorgu için çalıştırmak hem yavaş hem pahalı. Inference optimization tam bu noktada devreye giriyor.
Birkaç temel yaklaşım var:
- Quantization — modelin ağırlıklarını daha düşük hassasiyetle temsil etmek. 32-bit float yerine 4-bit kullanmak modeli küçültür, hızlandırır; kaliteden biraz ödün verilir.
- KV Cache — aynı conversation içinde daha önce hesaplanan değerleri tekrar hesaplamamak için önbellek kullanmak. Uzun konuşmalarda büyük hız kazandırır.
- Distillation — büyük bir modelden daha küçük bir modeli, öğretmen-öğrenci mantığıyla eğitmek.
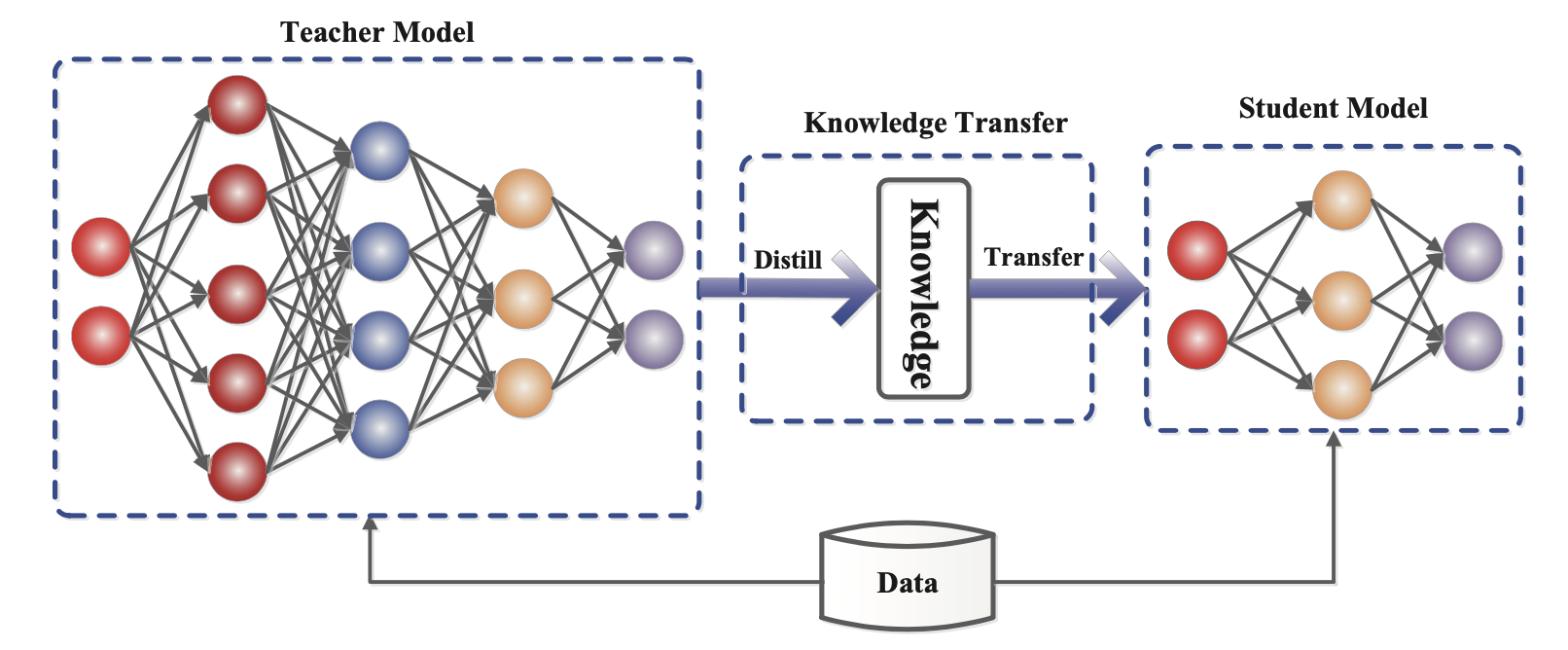
Distillation'da Teacher Model, Knowledge Transfer mekanizmasıyla öğrendiği bilgiyi Student Model'e aktarır. Student, öğretmenin ham verisini değil onun çıktılarını ve davranışını taklit ederek eğitilir. GPT-4o Mini bu mantıkla ortaya çıktı — daha küçük, daha hızlı, makul düzeyde yetenekli.
Bu optimizasyonlar olmadan bugünkü ölçekte milyonlarca kullanıcıya LLM sunmak mümkün olmazdı.
Bir sonraki parçada daha derine ineceğiz. Sorularınız varsa her zaman iletişime geçebilirsiniz.
