16 Nisan 2026. Anthropic, Claude Opus 4.7'yi genel kullanıma açtı.
Yazılım mühendisliği odaklı bu büyük güncelleme görüntü çözünürlüğünü üç kattan fazla artırıyor, daha derin muhakeme getiriyor ve daha ince ayarlı kontrol mekanizmaları sunuyor. GPT-5.4 ve Gemini 3.1 Pro ile kıyaslayan resmi benchmark grafikleri de yayınlandı.
Ama önce başa dönelim: Claude nedir, neden önemlidir?
Claude Nedir?
Claude, San Francisco merkezli yapay zeka şirketi Anthropic tarafından geliştirilen bir büyük dil modelidir (LLM). ChatGPT ve Gemini ile aynı kategoride yer alır; metin üretmek, kod yazmak, analiz yapmak, soru yanıtlamak ve karmaşık görevleri adım adım çözmek için kullanılır.
Anthropic'i diğerlerinden ayıran temel iddia: güvenlik odaklı yapay zeka araştırması. Şirket, "Constitutional AI" adını verdiği bir yaklaşımla Claude'u yalnızca yetenekli değil, aynı zamanda hizalanmış (aligned) ve dürüst olmaya yönlendirilmiş bir model olarak eğitiyor.
Claude Ailesi
Claude modelleri üç seviyeli bir yapıda sunuluyor:
| Model | Özellik |
|---|
| Haiku | Hızlı, hafif görevler için |
| Sonnet | Hız ve güç dengesi |
| Opus | En yetenekli, en derin muhakeme |
Versiyon numarası nesli gösterir — 4.7, şimdiye kadarki en yeni ve en güçlü Opus.
Claude, Claude.ai arayüzü üzerinden doğrudan kullanılabildiği gibi API aracılığıyla geliştiricilerin uygulamalarına da entegre edilebiliyor. Amazon Bedrock, Google Cloud Vertex AI ve Microsoft Foundry üzerinden de erişilebilir.
Benchmark Karşılaştırması: Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro
Anthropic, yayınla birlikte rakiplerle doğrudan karşılaştıran kapsamlı bir benchmark tablosu yayınladı.
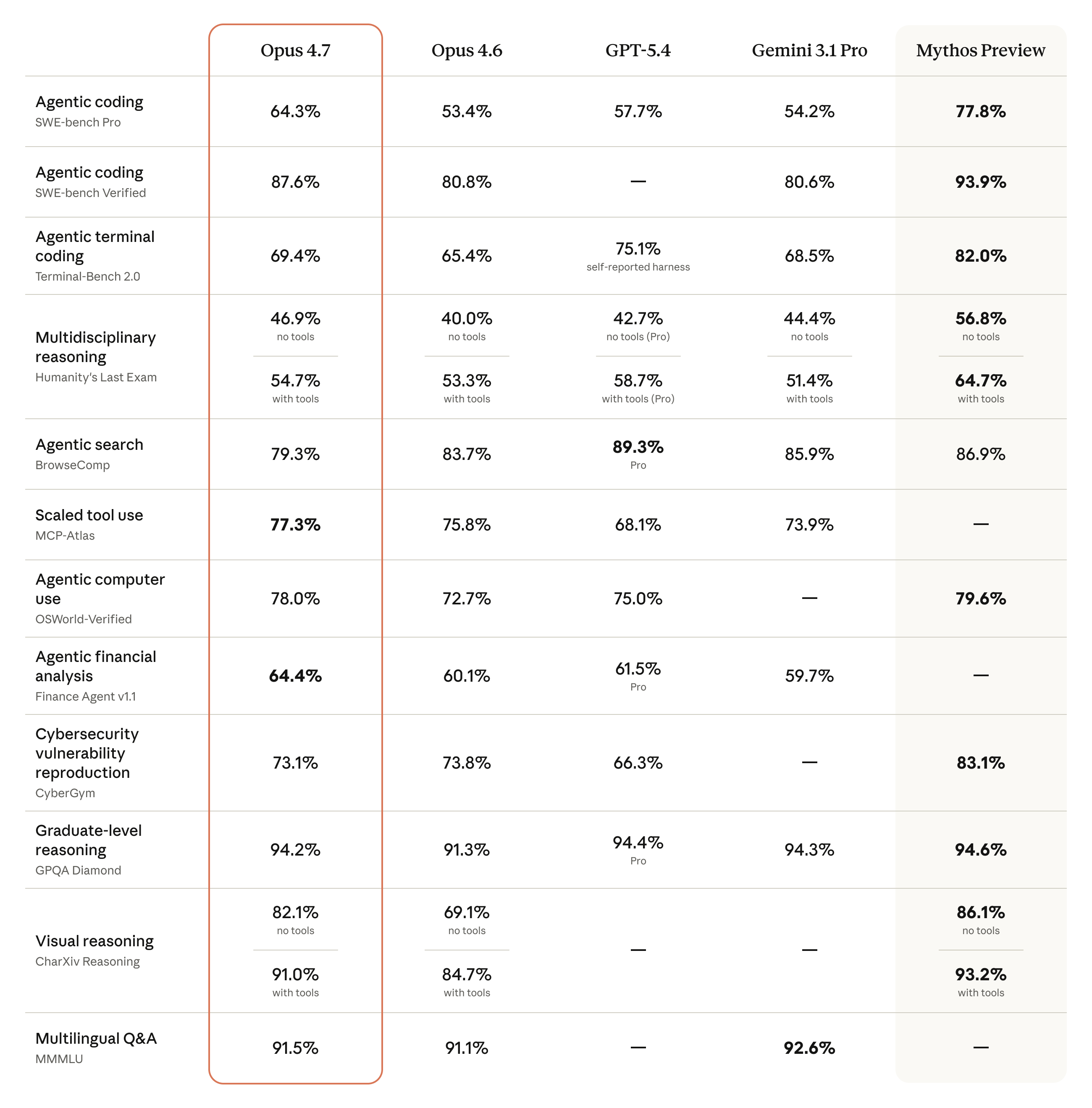
Öne çıkan sonuçlar:
| Benchmark | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|
| Agentic coding (SWE-bench Pro) | 64.3% | 53.4% | 57.7% | 54.2% |
| Agentic coding (SWE-bench Verified) | 87.6% | 80.8% | — | 80.6% |
| Terminal kodlama (Terminal-Bench 2.0) | 69.4% | 65.4% | 75.1%* | 68.5% |
| Çok disiplinli muhakeme (HLE, araçsız) | 46.9% | 40.0% | 42.7% | 44.4% |
| Çok disiplinli muhakeme (HLE, araçlı) | 54.7% | 53.3% | 58.7% | 51.4% |
| Agentic arama (BrowseComp) | 79.3% | 83.7% | 89.3% | 85.9% |
| Ölçekli araç kullanımı (MCP-Atlas) | 77.3% | 75.8% | 68.1% | 73.9% |
| Agentic bilgisayar kullanımı (OSWorld) | 78.0% | 72.7% | 75.0% | — |
| Finansal analiz (Finance Agent v1.1) | 64.4% | 60.1% | 61.5% | 59.7% |
| Lisansüstü muhakeme (GPQA Diamond) | 94.2% | 91.3% | 94.4% | 94.3% |
| Görsel muhakeme (CharXiv, araçlı) | 91.0% | 84.7% | — | — |
| Çok dilli soru-cevap (MMMLU) | 91.5% | 91.1% | — | 92.6% |
*GPT-5.4 Terminal-Bench skoru kendi raporlama yöntemiyle ölçüldü
1. Bilgi Çalışması: GDPVal-AA
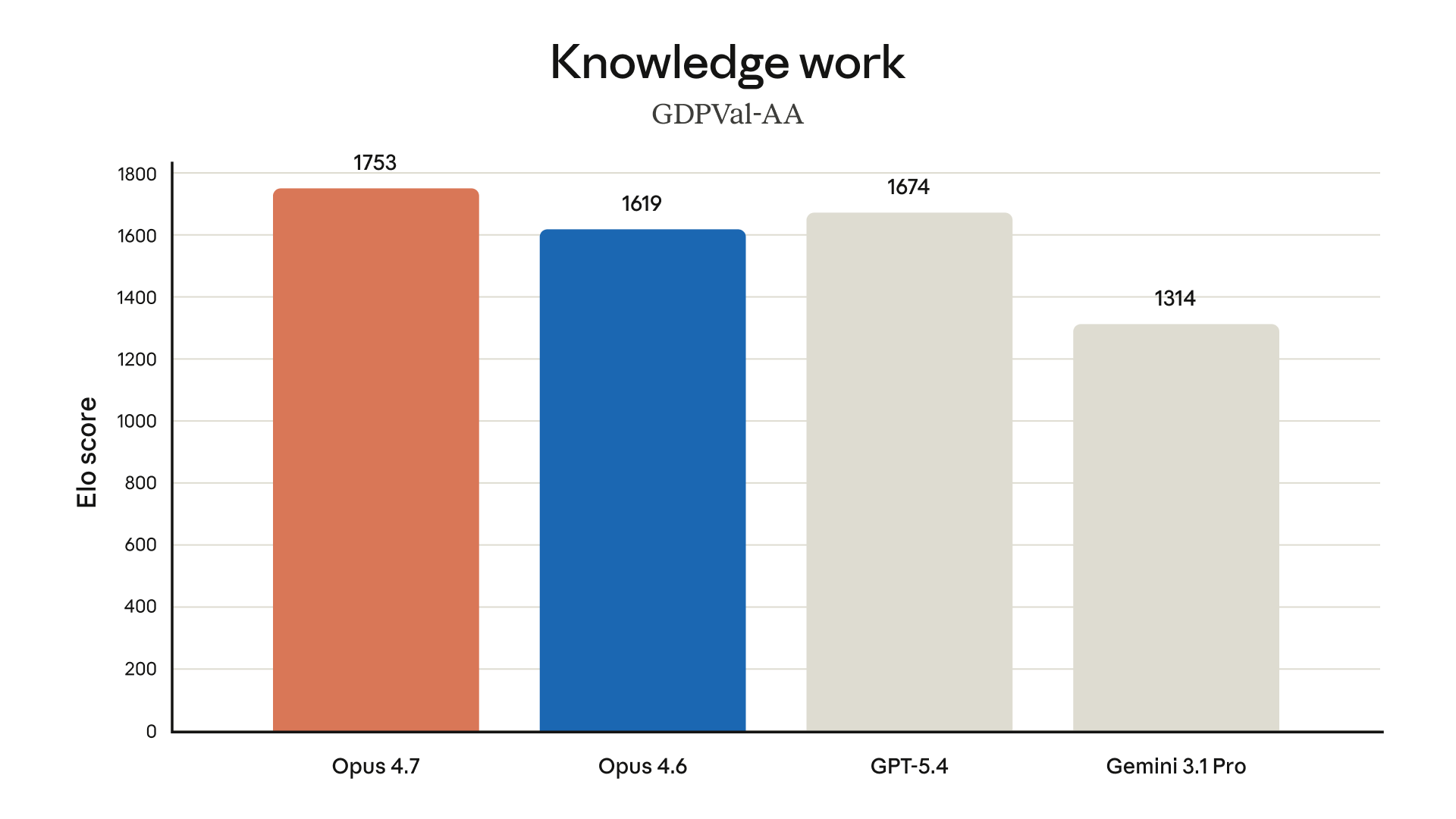
GDPVal-AA, ekonomi ve iş analitiği odaklı bir bilgi çalışması değerlendirmesidir. Elo puan sistemiyle ölçülüyor:
- Opus 4.7: 1753 — birinci
- GPT-5.4: 1674
- Opus 4.6: 1619
- Gemini 3.1 Pro: 1314
Opus 4.7, bu kategoride hem GPT-5.4'ü hem de önceki nesli açık ara geçiyor.
2. Görsel Navigasyon: ScreenSpot-Pro
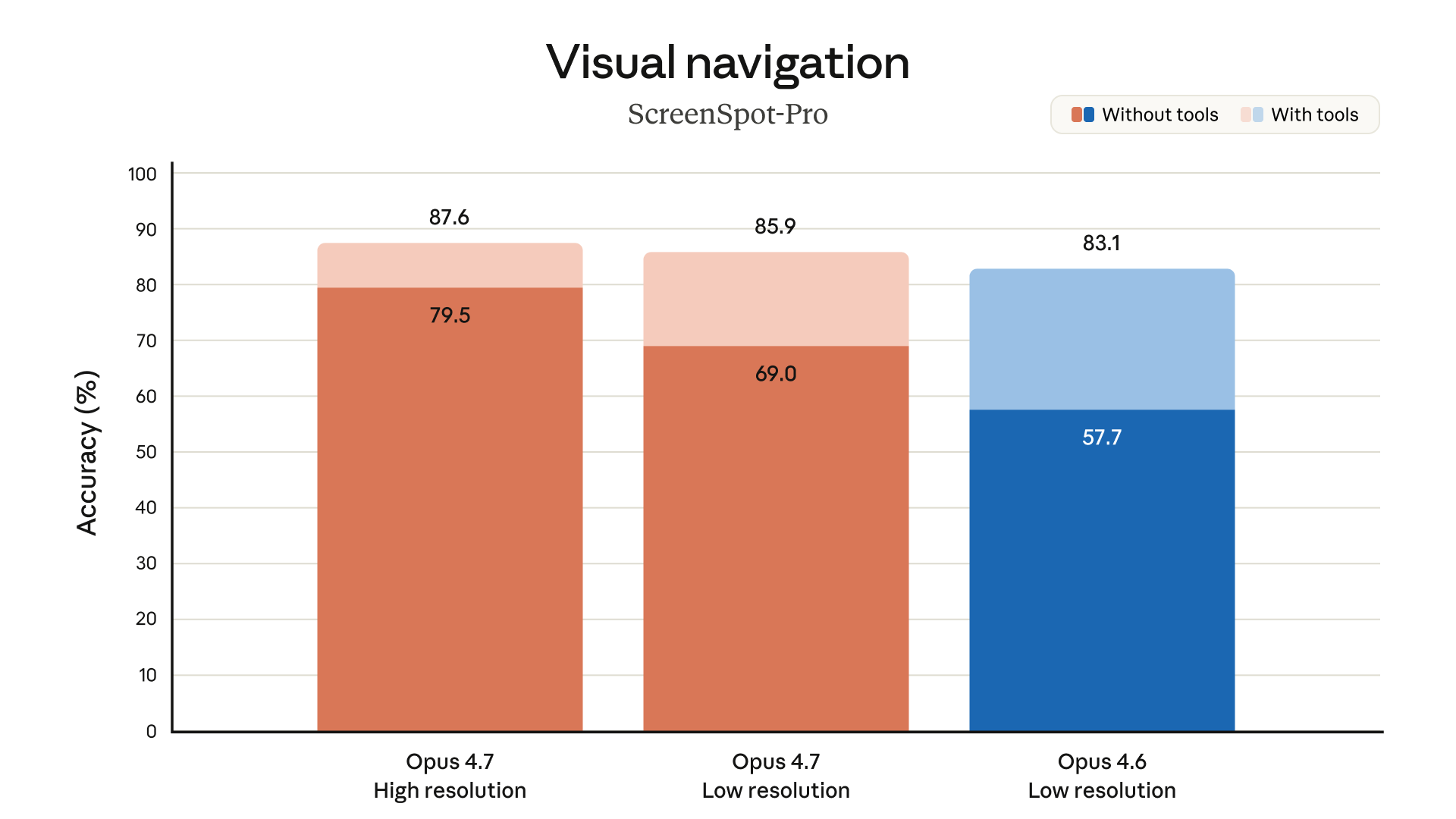
ScreenSpot-Pro, ekran arayüzlerinde gezinme ve görsel anlama kabiliyetini test ediyor. Sonuçlar çarpıcı:
- Opus 4.7 (yüksek çözünürlük): %87.6 doğruluk
- Opus 4.7 (düşük çözünürlük): %85.9
- Opus 4.6 (düşük çözünürlük): %83.1
Yüksek çözünürlük modu — yani Opus 4.7'nin yeni 3.75 megapiksel kapasitesi — bu farkı doğrudan yaratıyor.
3. Belge Muhakemesi: OfficeQA Pro
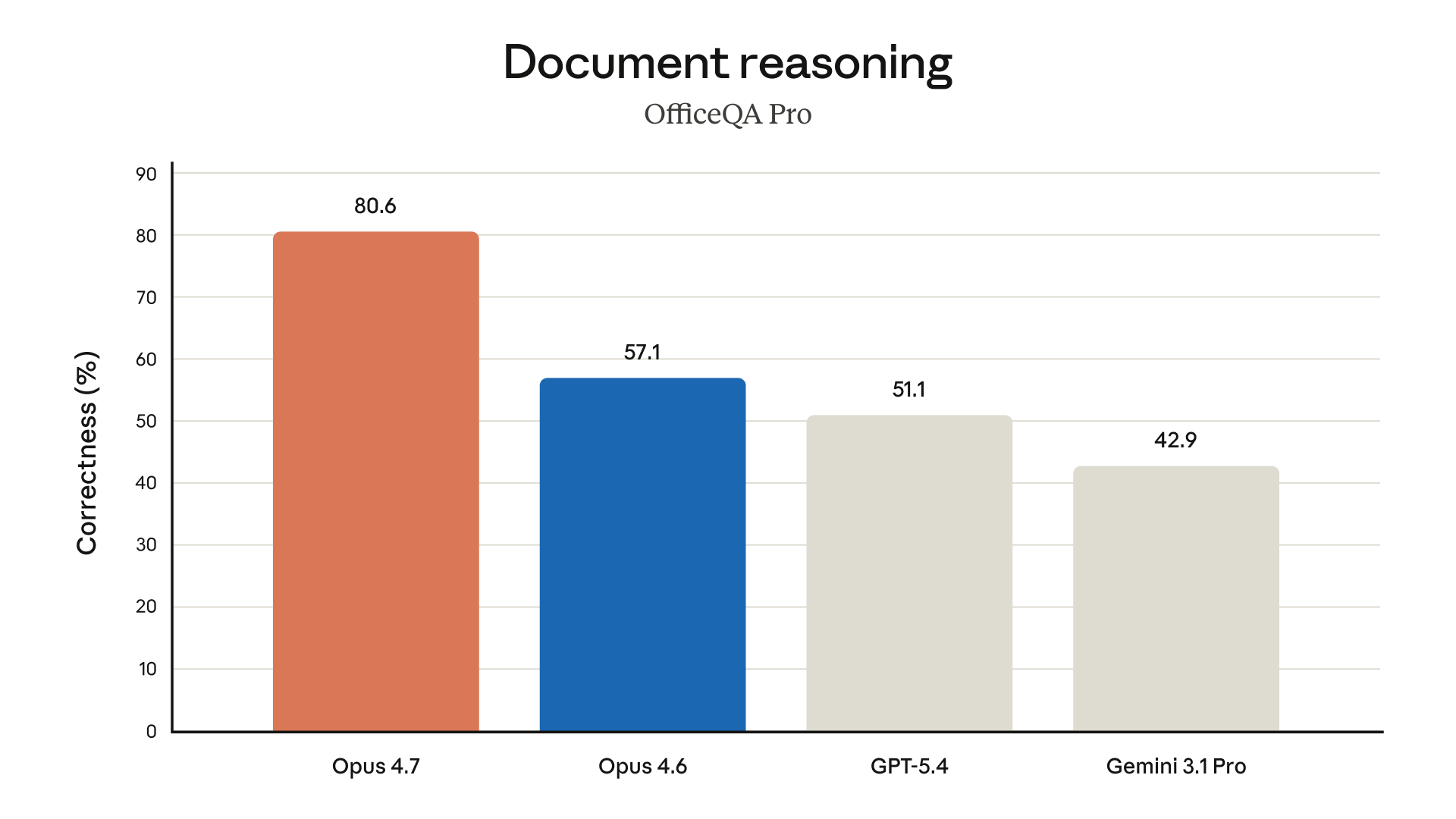
OfficeQA Pro, gerçek ofis belgelerini anlama ve sorulara doğru yanıt verme kabiliyetini ölçüyor:
- Opus 4.7: %80.6 — birinci ve açık ara
- Opus 4.6: %57.1
- GPT-5.4: %51.1
- Gemini 3.1 Pro: %42.9
Bu benchmark, önceki nesle göre %41 iyileşme anlamına geliyor. Belge işleme odaklı iş akışları için ciddi bir fark.
4. Uzun Vadeli Tutarlılık: Vending-Bench 2
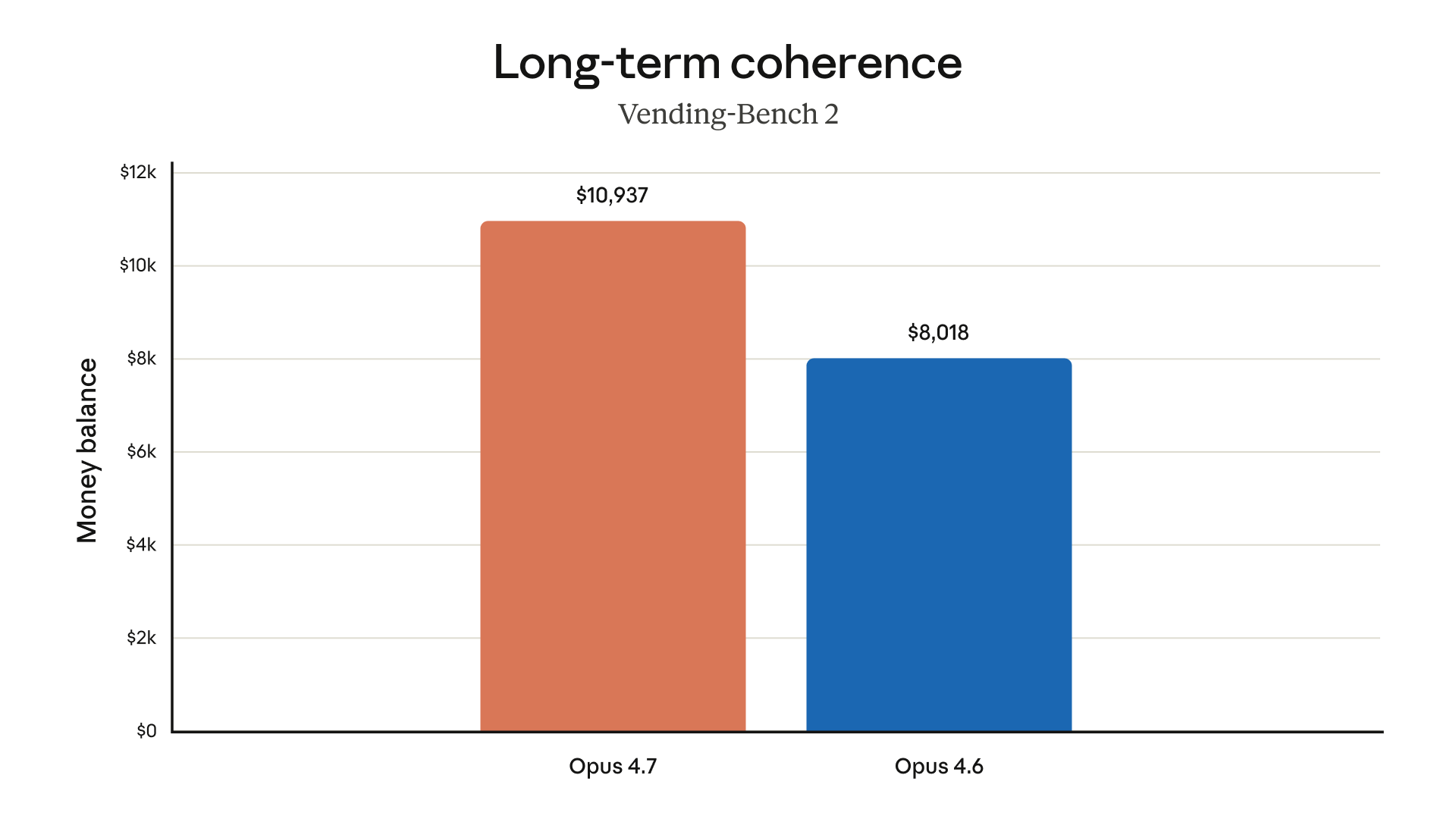
Vending-Bench 2, modelin uzun süreli özerk görevlerdeki tutarlılığını ve iş tamamlama başarısını ölçüyor. Para bakiyesiyle ifade edilen skor, gerçek dünya senaryolarında ne kadar değer ürettiğini temsil ediyor:
- Opus 4.7: $10,937
- Opus 4.6: $8,018
Bu, otonom uzun süreli görevlerde yaklaşık %36 iyileşme.
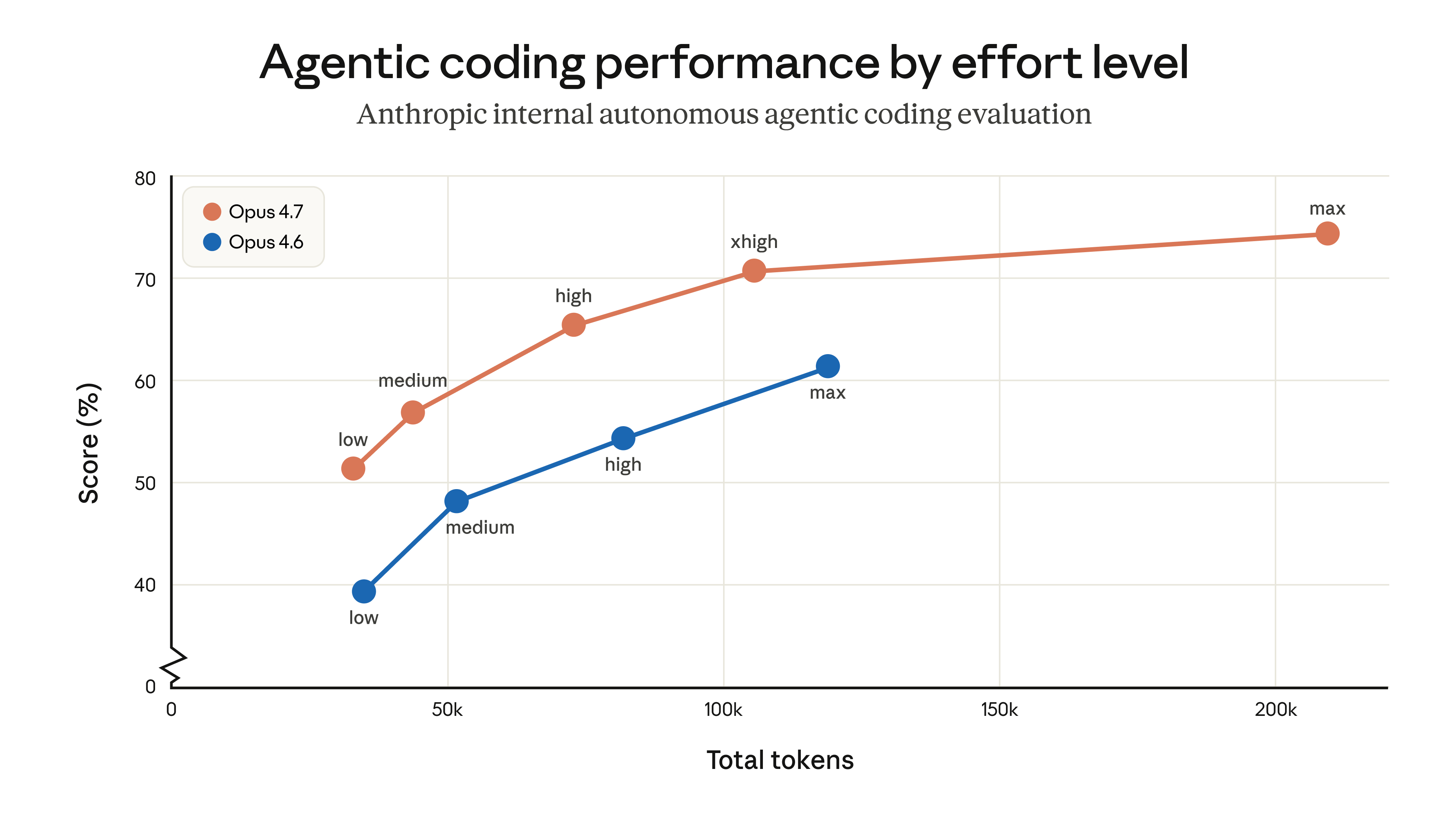
Bu grafik, yeni xhigh effort seviyesinin neden önemli olduğunu gösteriyor.
Opus 4.7 ile xhigh effort (~100K token), Opus 4.6'nın tam max effort (~125K token) ile elde ettiği sonucu daha az token harcayarak geçiyor. Maliyet-performans dengesi için kritik bir veri.
Effort seviyeleri karşılaştırması:
Opus 4.7: low(51%) → medium(57%) → high(66%) → xhigh(71%) → max(75%)
Opus 4.6: low(39%) → medium(48%) → high(55%) → max(62%)
6. Hizalanmış Davranış (Güvenlik)
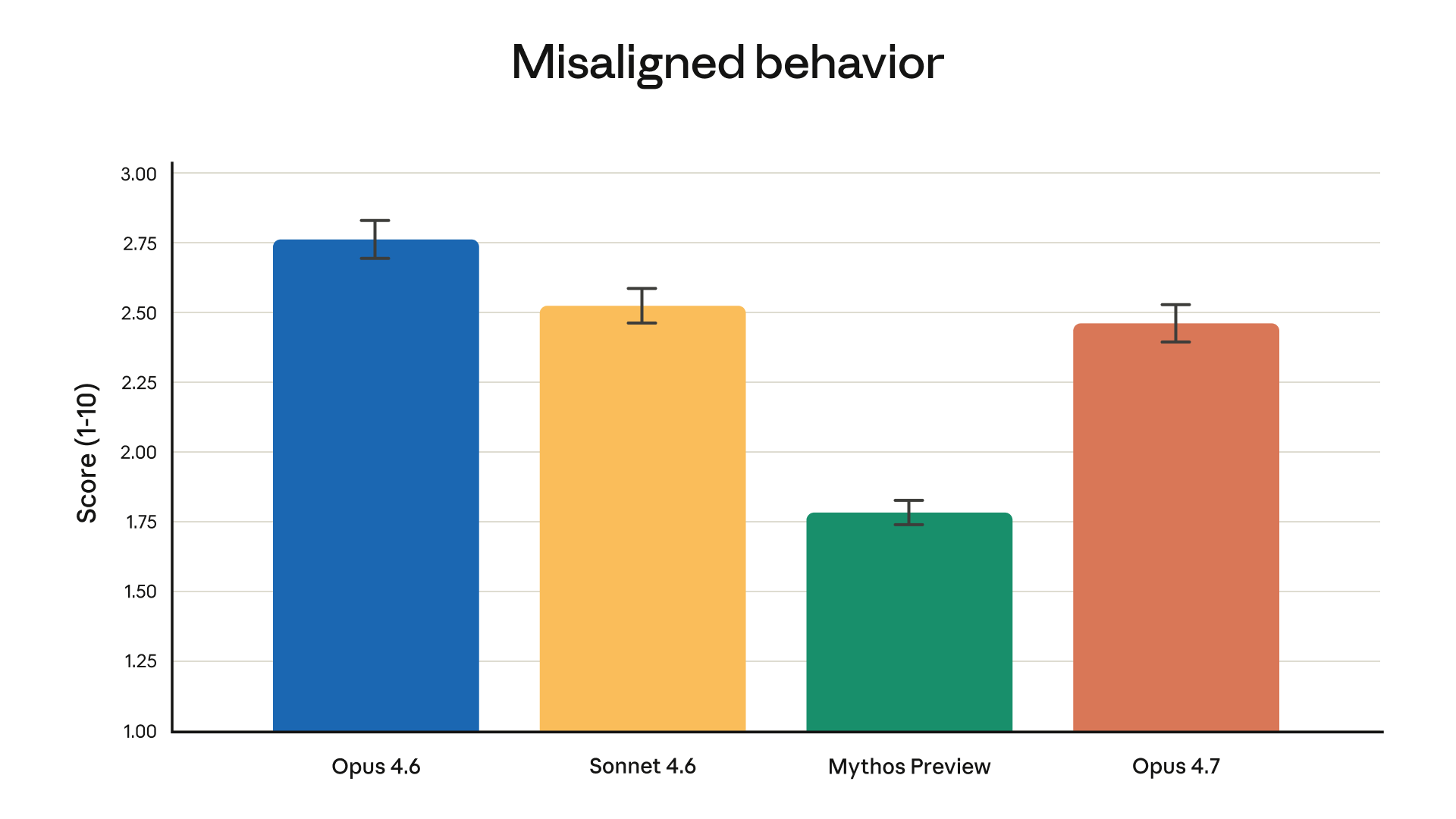
Bu grafik düşük skoru daha iyi olarak ölçüyor — yani modelin ne kadar az hizalanmamış davranış sergilediğini gösteriyor:
- Opus 4.6: 2.75 (en kötü)
- Sonnet 4.6: 2.52
- Opus 4.7: 2.46 — Opus serisindeki en iyi skor
- Mythos Preview: 1.78
Opus 4.7, önceki Opus'a kıyasla daha güvenli davranış sergiliyor.
Yeni xhigh Effort Seviyesi
API'daki effort parametresi, modelin ne kadar derin düşündüğünü kontrol ediyor. Opus 4.7, high ile max arasına yeni bir seçenek ekliyor:
low → medium → high → xhigh → max
Yukarıdaki grafik bunu somutlaştırıyor: xhigh, Opus 4.6'nın max'ından daha iyi performans gösterirken daha az token tüketiyor.
Görüntü İşlemede 3× Sıçrama
Önceki Claude modellerinin görüntü işleme kapasitesi sınırlıydı. Opus 4.7 bunu kökten değiştiriyor:
- Uzun kenar boyunca 2.576 piksele kadar işleme
- Yaklaşık 3.75 megapiksel — önceki neslin 3 katından fazlası
- Teknik diyagramlar, arayüz tasarımları ve belgeler için gelişmiş görsel anlama
ScreenSpot-Pro benchmark'ı bu farkı doğruluyor: Opus 4.7 yüksek çözünürlük (%87.6) vs Opus 4.6 düşük çözünürlük (%83.1).
Güvenlik: Cyber Verification Program
Anthropic, Opus 4.7'ye yüksek riskli siber güvenlik isteklerini otomatik olarak tespit eden bir güvenlik katmanı ekledi. Model, bu tür istekleri varsayılan olarak reddediyor.
Meşru kullanım için bir yol var: Cyber Verification Program. Sızma testi, güvenlik açığı araştırması veya kırmızı takım çalışması yapan güvenlik profesyonelleri bu programa başvurarak doğrulanmış erişim elde edebiliyor.
Fiyatlandırma
Liste fiyatları değişmedi:
| Kullanım | Fiyat |
|---|
| Giriş (input) | $5 / milyon token |
| Çıkış (output) | $25 / milyon token |
Ancak dikkat: Opus 4.7 yeni bir tokenizer kullanıyor. Aynı metin, önceki versiyona kıyasla yaklaşık %0–35 daha fazla token tüketebiliyor. Yüksek effort seviyeleri de daha fazla çıktı tokeni üretiyor.
API Kullanımı
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[
{"role": "user", "content": "Karmaşık bir sistemi nasıl optimize edersin?"}
]
)
print(message.content)
Model ID: claude-opus-4-7
Erişim noktaları: Claude.ai, Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry.
Opus 4.6 ile Özet Karşılaştırma
| Özellik | Opus 4.6 | Opus 4.7 |
|---|
| Görüntü çözünürlüğü | ~1 megapiksel | ~3.75 megapiksel |
| Effort seviyeleri | low/medium/high/max | + yeni xhigh |
| SWE-bench Verified | 80.8% | 87.6% |
| OfficeQA Pro | 57.1% | 80.6% |
| GDPVal-AA (Elo) | 1619 | 1753 |
| Hizalanmış davranış | 2.75 | 2.46 (iyileşme) |
| Fiyat (input) | $5/M token | $5/M token |
| Tokenizer | Eski | Yeni (~%0–35 fark) |
Sonuç
Opus 4.7, kademeli bir iyileştirme değil. Belge muhakemesinde %41 artış, SWE-bench'te en güçlü Anthropic skoru, görüntü işlemede 3× sıçrama — bunlar benchmark rakamlarıyla doğrulanmış gerçek kazanımlar.
GPT-5.4 bazı alanlarda (BrowseComp, terminal kodlama) hâlâ güçlü. Ancak bilgi çalışması, belge işleme, finansal analiz ve görsel görevlerde Opus 4.7 açık fark atıyor.
Fiyat sabit — ama yeni tokenizer nedeniyle gerçek maliyetin biraz artabileceğini hesaba katmak gerekiyor.
claude-opus-4-6 üzerinde çalışıyorsanız, 4.7'ye geçiş için iyi bir zaman.
