April 16, 2026. Anthropic shipped Claude Opus 4.7 into general availability.
The update focuses on software engineering excellence, triples image resolution, and introduces a new effort control layer. Anthropic also published direct benchmark comparisons against GPT-5.4 and Gemini 3.1 Pro.
If you're new to Claude, here's what it is and why the model family matters — then we'll get into the numbers.
What Is Claude?
Claude is a large language model (LLM) developed by Anthropic, an AI safety company founded in 2021 and headquartered in San Francisco. It competes directly with OpenAI's GPT-4o/GPT-5.4 and Google's Gemini — used for writing, coding, analysis, question answering, and complex multi-step reasoning.
Anthropic's differentiating claim is safety-focused AI research. The company trains Claude using Constitutional AI, a method designed to produce models that are not just capable but honest and aligned with human values.
The Claude Model Family
| Model | Best For |
|---|
| Haiku | Fast, lightweight tasks |
| Sonnet | Balanced speed and power |
| Opus | Maximum capability and reasoning depth |
Version numbers indicate generation. 4.7 is the newest and most capable Opus to date.
Benchmark Results: Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro
Anthropic published a full benchmark comparison table at launch.
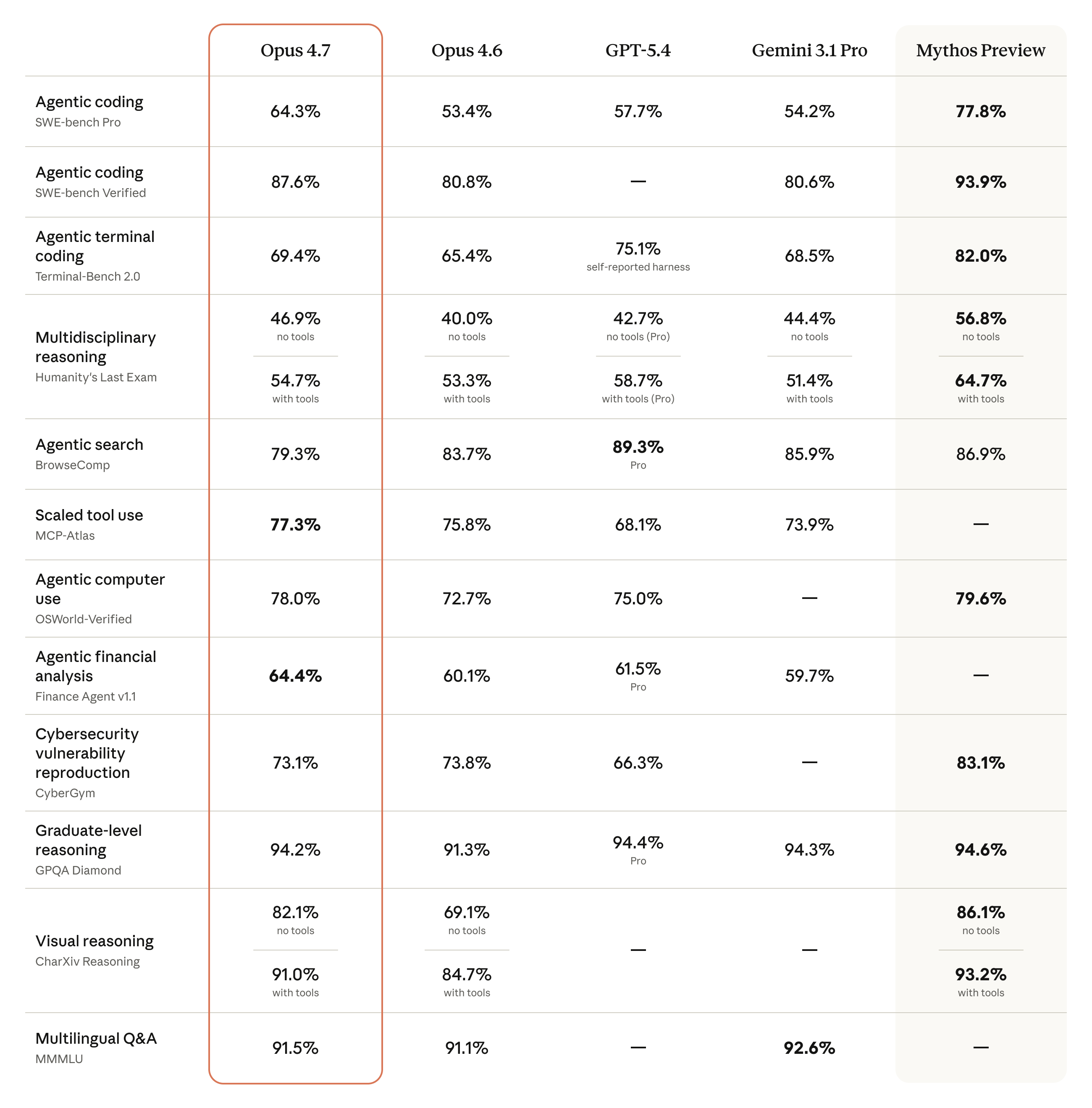
Key results:
| Benchmark | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|
| Agentic coding (SWE-bench Pro) | 64.3% | 53.4% | 57.7% | 54.2% |
| Agentic coding (SWE-bench Verified) | 87.6% | 80.8% | — | 80.6% |
| Terminal coding (Terminal-Bench 2.0) | 69.4% | 65.4% | 75.1%* | 68.5% |
| Multidisciplinary reasoning, no tools (HLE) | 46.9% | 40.0% | 42.7% | 44.4% |
| Multidisciplinary reasoning, with tools (HLE) | 54.7% | 53.3% | 58.7% | 51.4% |
| Agentic search (BrowseComp) | 79.3% | 83.7% | 89.3% | 85.9% |
| Scaled tool use (MCP-Atlas) | 77.3% | 75.8% | 68.1% | 73.9% |
| Agentic computer use (OSWorld-Verified) | 78.0% | 72.7% | 75.0% | — |
| Financial analysis (Finance Agent v1.1) | 64.4% | 60.1% | 61.5% | 59.7% |
| Graduate-level reasoning (GPQA Diamond) | 94.2% | 91.3% | 94.4% | 94.3% |
| Visual reasoning (CharXiv, with tools) | 91.0% | 84.7% | — | — |
| Multilingual Q&A (MMMLU) | 91.5% | 91.1% | — | 92.6% |
*GPT-5.4 Terminal-Bench score uses self-reported harness
Knowledge Work: GDPVal-AA
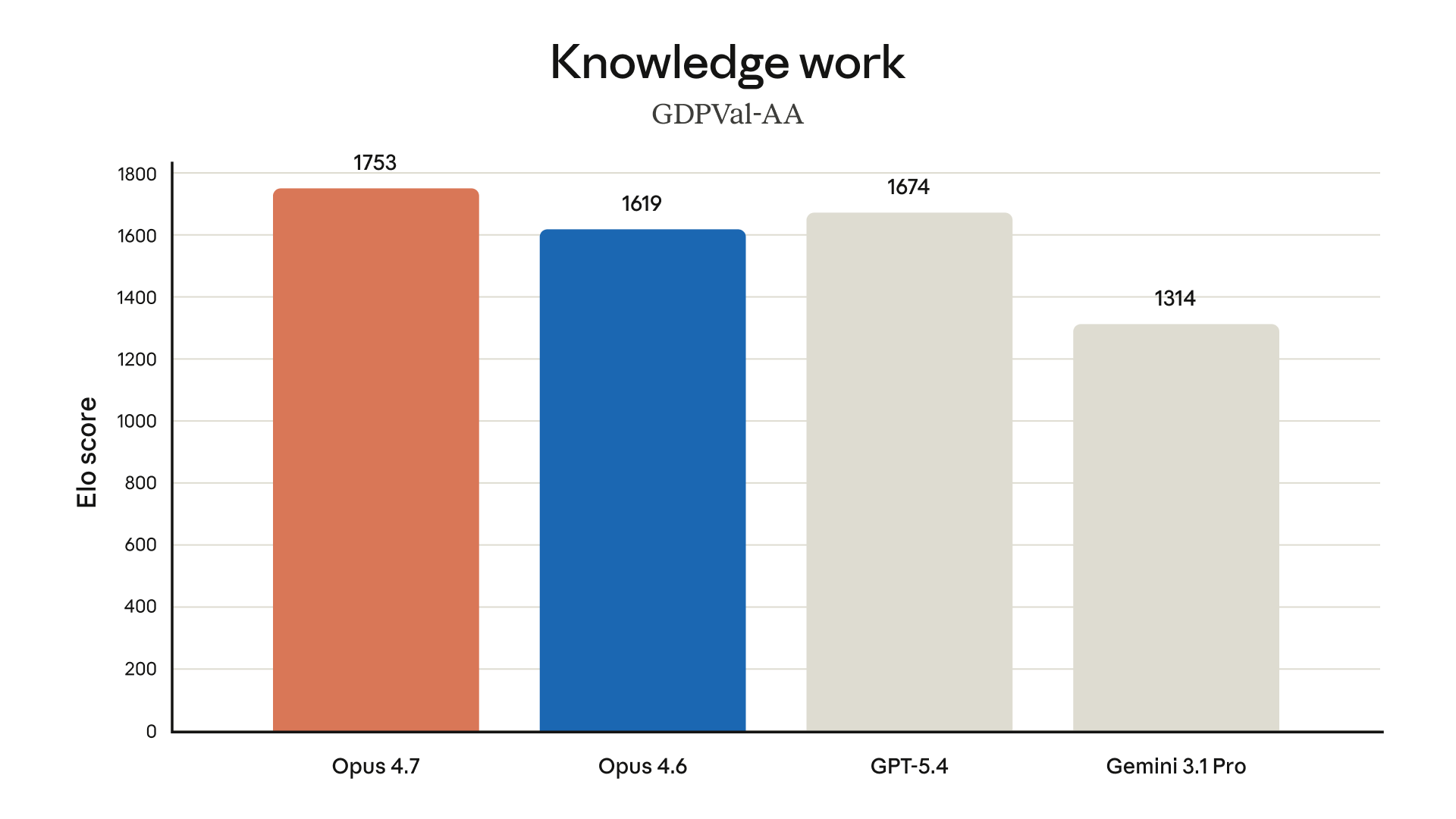
GDPVal-AA measures economic analysis and business intelligence tasks using an Elo scoring system:
- Opus 4.7: 1753 — first place
- GPT-5.4: 1674
- Opus 4.6: 1619
- Gemini 3.1 Pro: 1314
Opus 4.7 leads GPT-5.4 by 79 Elo points here — meaningful given how closely models cluster in most benchmarks.
Document Reasoning: OfficeQA Pro
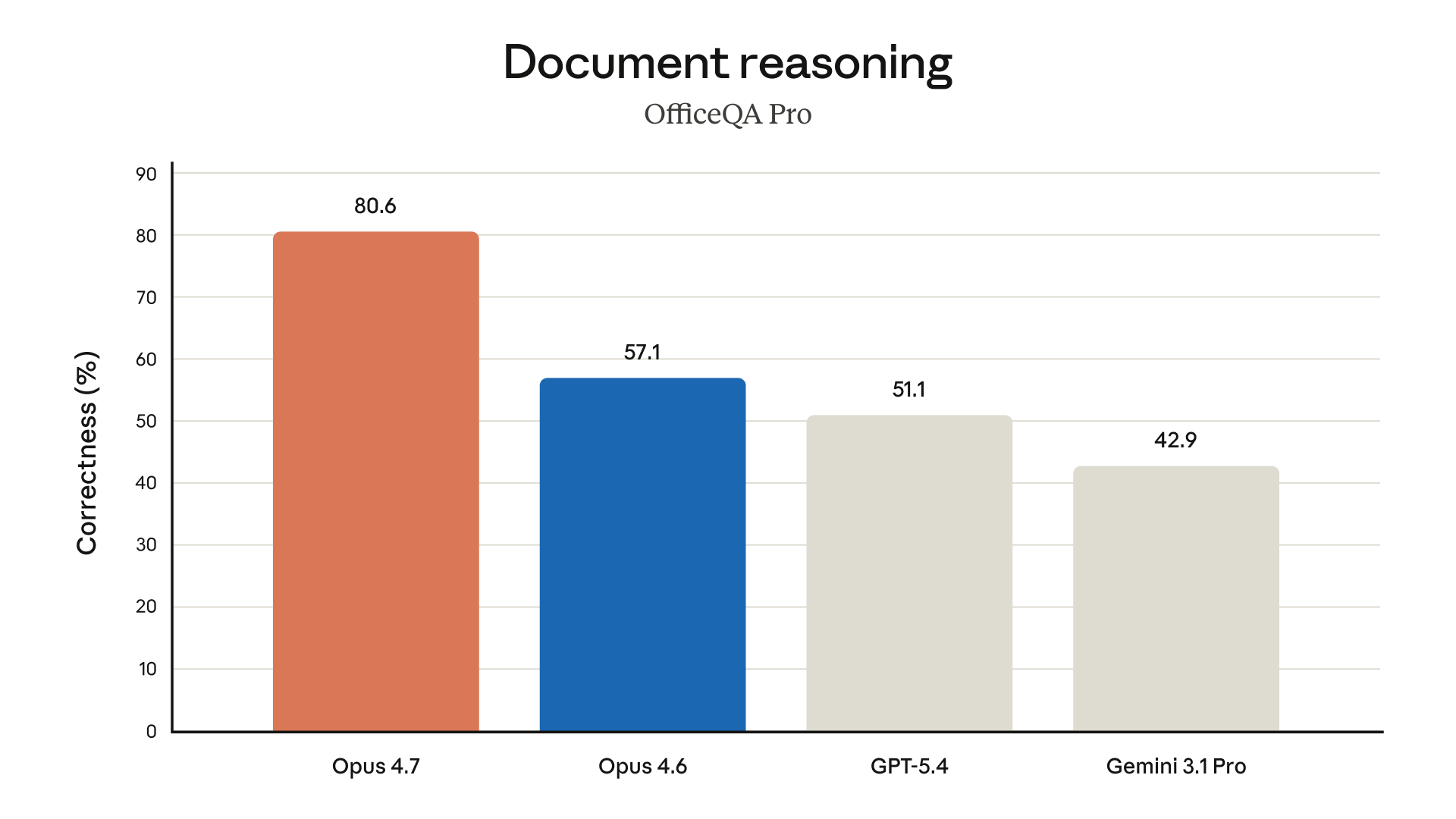
OfficeQA Pro tests comprehension of real office documents — spreadsheets, presentations, reports:
- Opus 4.7: 80.6% — first and by a wide margin
- Opus 4.6: 57.1%
- GPT-5.4: 51.1%
- Gemini 3.1 Pro: 42.9%
That's a 41% improvement over the previous generation. For document-heavy workflows, this is the standout result.
Visual Navigation: ScreenSpot-Pro
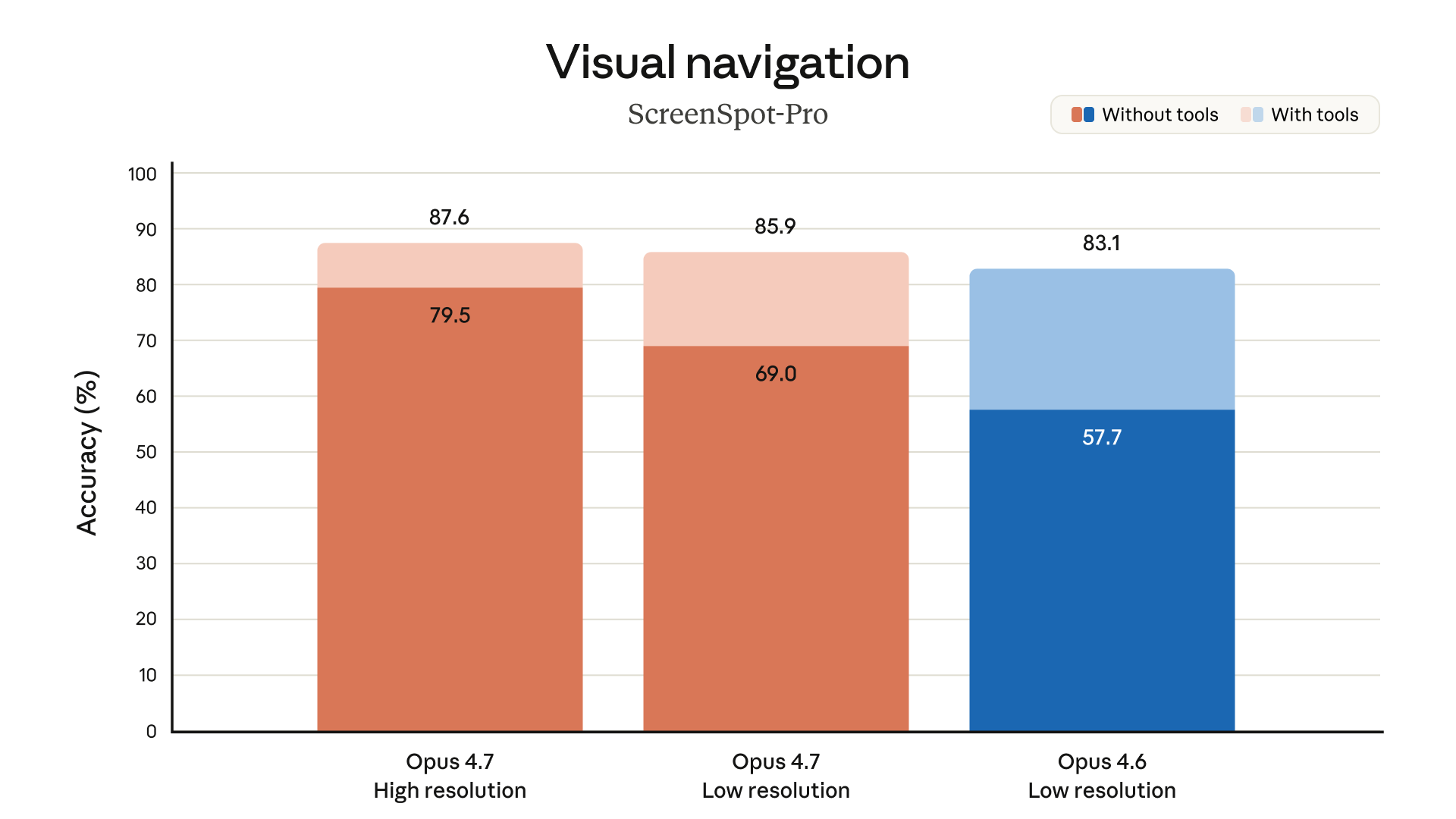
ScreenSpot-Pro tests UI navigation and visual understanding — clicking the right element in a screenshot:
- Opus 4.7, high resolution: 87.6%
- Opus 4.7, low resolution: 85.9%
- Opus 4.6, low resolution: 83.1%
The high-resolution mode — made possible by the new 3.75MP input capacity — is what drives the top result. The same model at lower resolution still outperforms the previous generation.
Long-Term Coherence: Vending-Bench 2
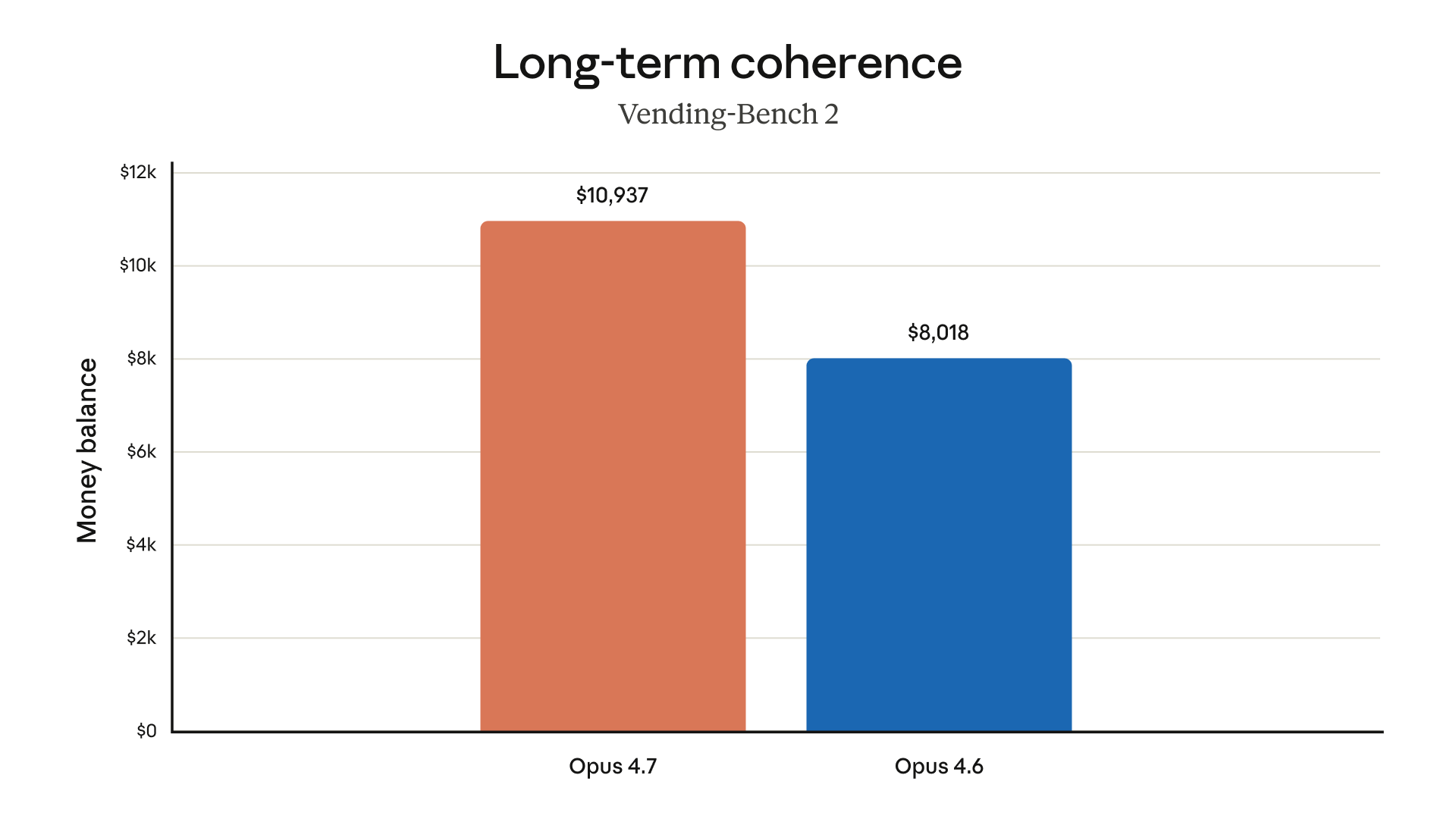
Vending-Bench 2 evaluates sustained autonomous task execution over long horizons. The money balance metric represents real-world value generated:
- Opus 4.7: $10,937
- Opus 4.6: $8,018
Approximately 36% improvement in long-horizon autonomous work.
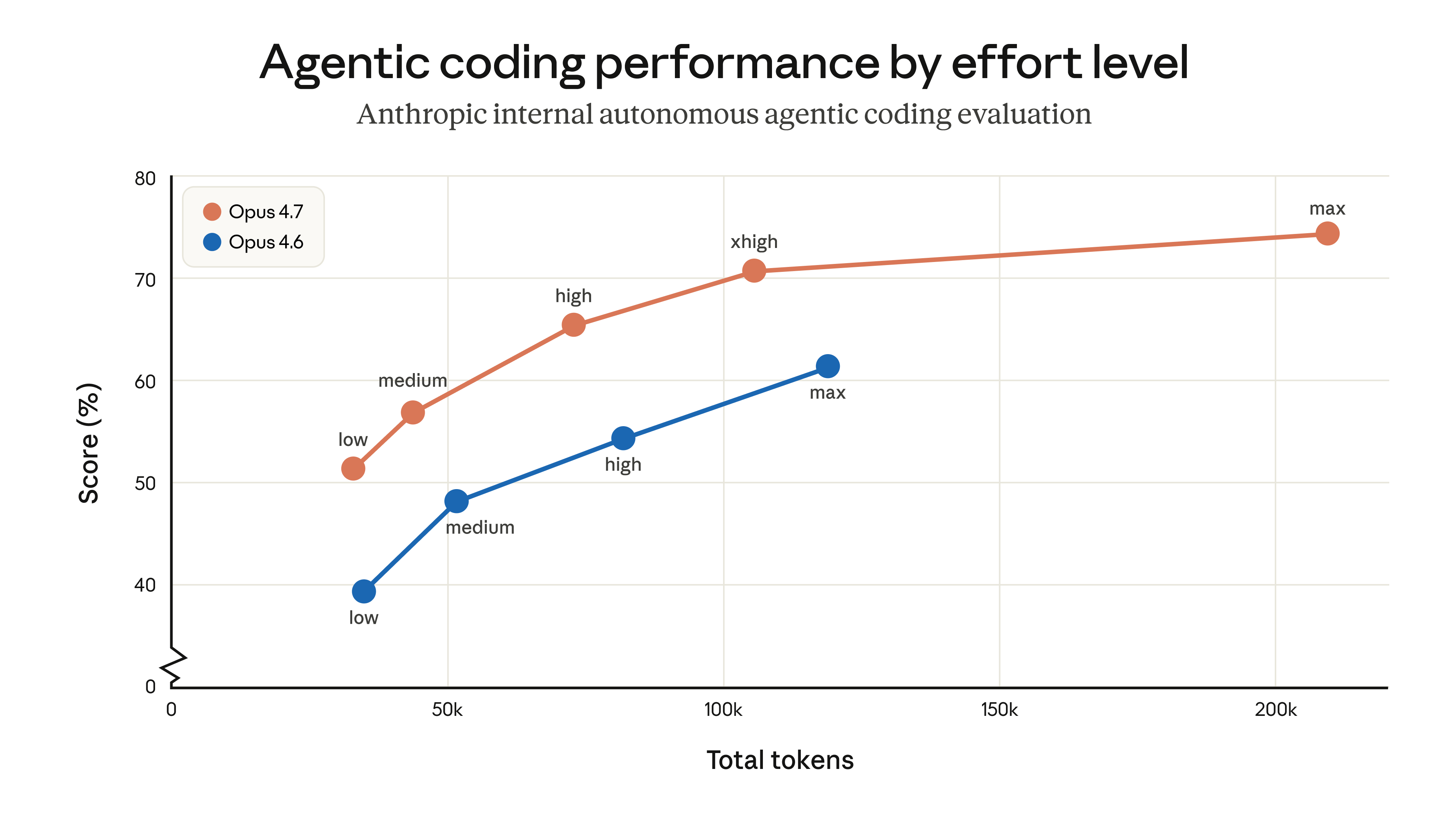
This chart explains why the new xhigh effort level matters.
Opus 4.7 at xhigh (~100K tokens) surpasses Opus 4.6 at full max effort (~125K tokens) — better performance at lower token cost.
Full effort progression:
Opus 4.7: low(51%) → medium(57%) → high(66%) → xhigh(71%) → max(75%)
Opus 4.6: low(39%) → medium(48%) → high(55%) → max(62%)
Every effort level in Opus 4.7 outperforms its counterpart in Opus 4.6. The model is fundamentally stronger, not just better at max effort.
Safety: Misaligned Behavior
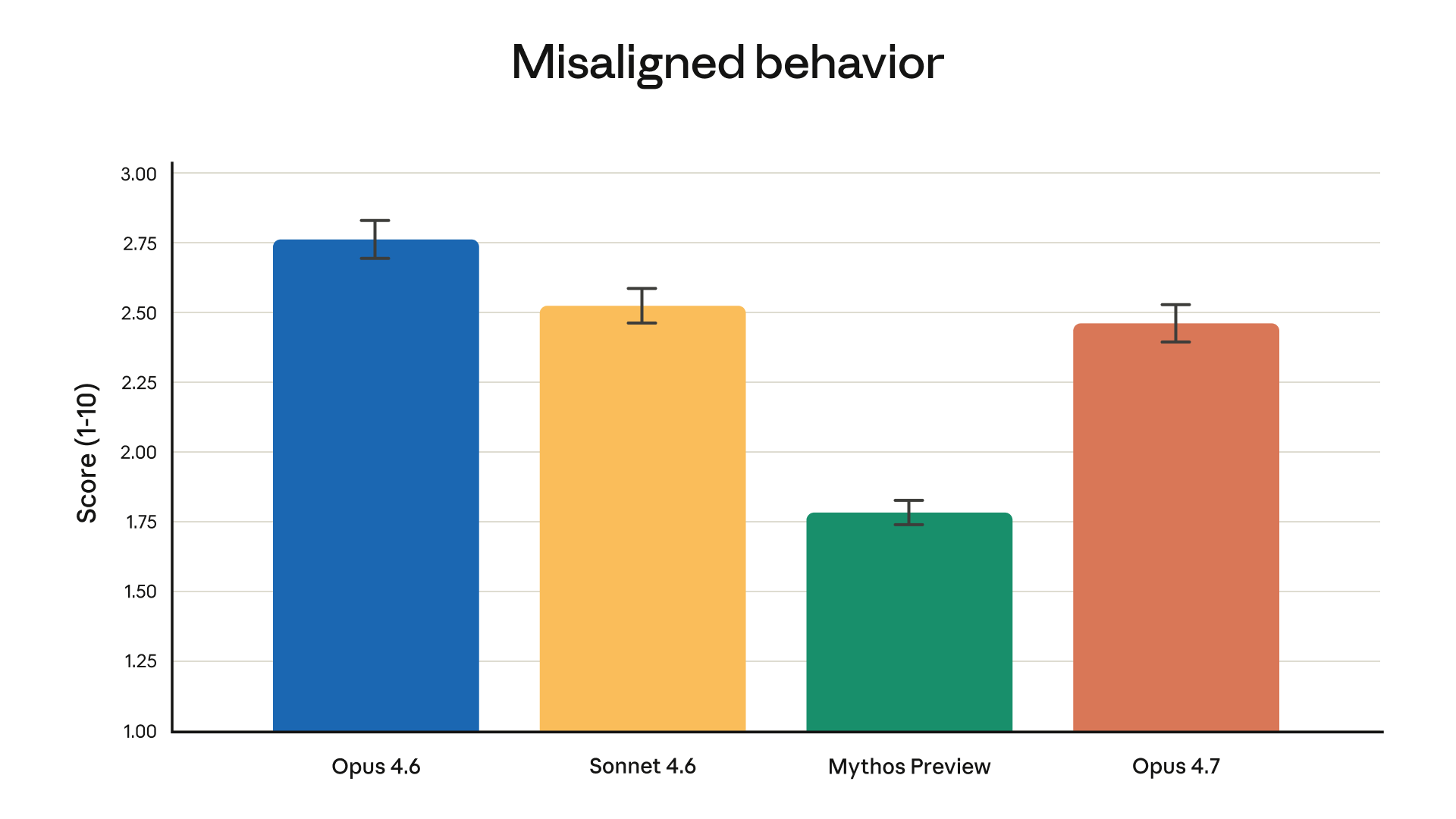
Lower score = less misaligned behavior = better:
- Opus 4.6: 2.75 (worst in the Claude family)
- Sonnet 4.6: 2.52
- Opus 4.7: 2.46 — best in the Opus series
- Mythos Preview: 1.78
Opus 4.7 improves on the previous Opus in both capability and safety alignment. The model also includes automatic detection of high-risk cybersecurity requests.
Security professionals can apply to the new Cyber Verification Program for verified access to penetration testing and vulnerability research use cases.
What Changed: Feature Summary
3× Vision Upgrade
- Images up to 2,576 pixels on the long edge
- Approximately 3.75 megapixels — 3× higher than previous Claude models
- Directly responsible for the ScreenSpot-Pro improvement above
New xhigh Effort Level
low → medium → high → xhigh → max
Finer control over the reasoning-latency tradeoff. For most complex tasks, xhigh hits the sweet spot.
Software Engineering Improvements
Better output verification before reporting results — the model checks rather than guesses. Prompts written for 4.6 may need retuning due to improved instruction-following.
Pricing and Migration
List prices are unchanged:
| Usage | Price |
|---|
| Input tokens | $5 / million |
| Output tokens | $25 / million |
Important: Opus 4.7 uses a new tokenizer. The same content may use 0–35% more tokens depending on type. Real costs may increase slightly.
Higher effort levels produce more output tokens — manage costs using effort parameters or task budgets.
API Usage
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[
{"role": "user", "content": "Explain the tradeoffs between microservices and monoliths."}
]
)
print(message.content)
Model ID: claude-opus-4-7
Available on: Claude.ai, Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry.
Bottom Line
The benchmark data tells a clear story: Opus 4.7 is meaningfully stronger than its predecessor and competitive with GPT-5.4 across most domains.
Where Opus 4.7 leads: document reasoning (+41%), knowledge work (GDPVal-AA), agentic tool use (MCP-Atlas), financial analysis, long-horizon coherence.
Where GPT-5.4 still leads: agentic search (BrowseComp), terminal coding (with caveats on methodology).
Pricing is flat, but the tokenizer change means real costs may tick up slightly.
If you're currently on claude-opus-4-6, now is a good time to migrate.
